A Long-Term Archival Pipeline for the Forschungsdatenplattform Stadt.Geschichte.Basel

Abstract
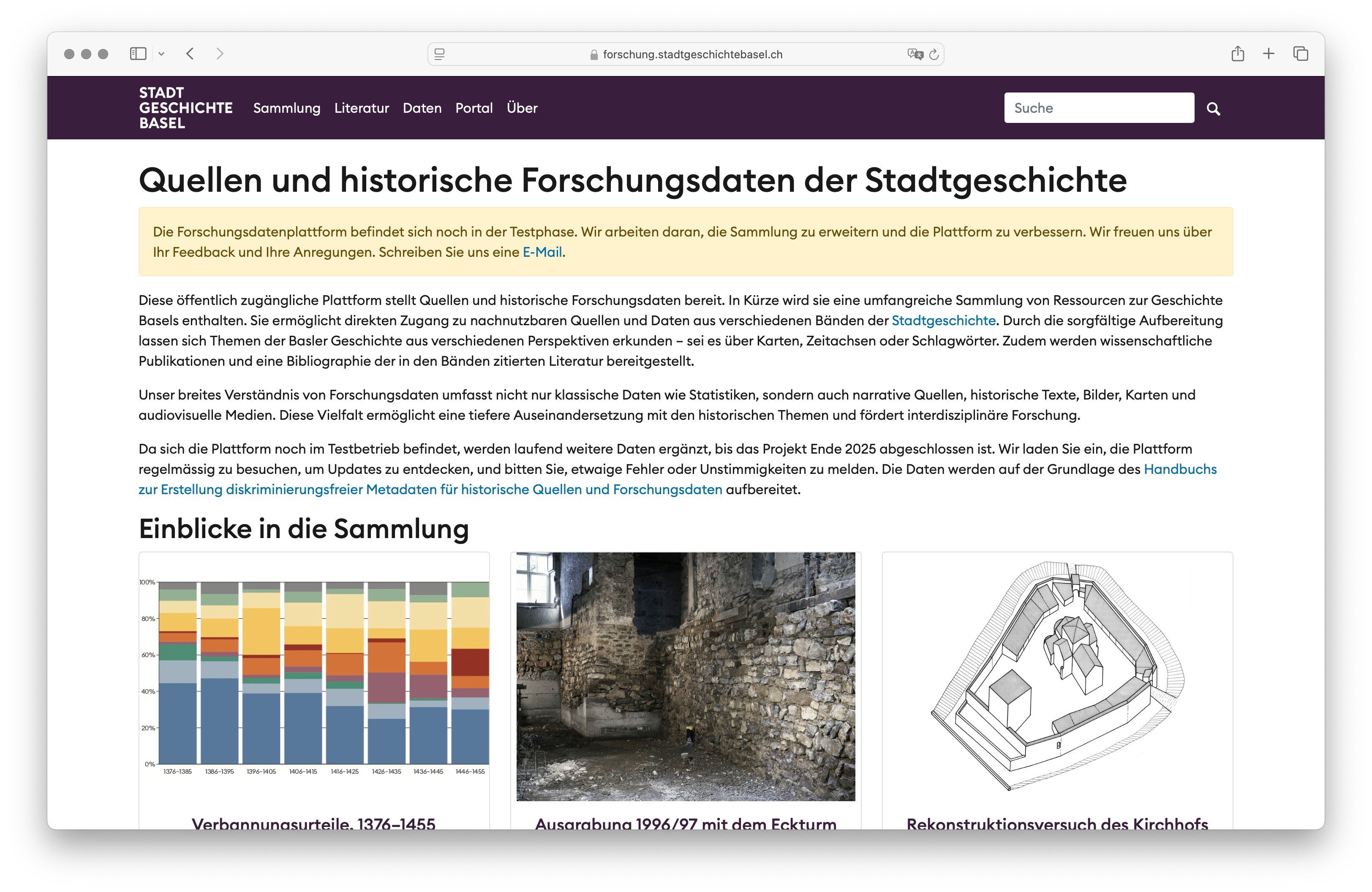
The Forschungsdatenplattform by Stadt.Geschichte.Basel provides open access to diverse historical materials relating to the city of Basel, including texts, images, statistical, and geospatial data. While technically robust and publicly available through GitHub Pages using the CollectionBuilder-CSV, our current infrastructure faces critical sustainability and scalability limitations.
At present, metadata and files are curated and managed using the Omeka-S instance provided by the University of Bern, from which we extract the data for display via CollectionBuilder. However, this setup introduces significant risks for long-term availability:
Omeka is not under our institutional control and may not remain permanently funded.
GitHub Pages is not suitable for serving large files or guaranteeing persistence.
CollectionBuilder lacks built-in support for versioning and persistent identifiers at the level required by research data infrastructures.
To address these challenges, we are implementing a transition pipeline to archive all metadata and associated files with DaSCH, leveraging its infrastructure for versioned, durable, and FAIR-compliant research data publication. The new pipeline includes:
Metadata harvesting and transformation from Omeka to the DaSCH data model.
Automated deposit and update routines using the DaSCH REST API, including support for versioning existing records.
Writing back stable DaSCH identifiers and access URLs to our public-facing platform, ensuring transparency and citability.
Preservation of hierarchical relationships and media metadata, aligned with our custom metadata model, which incorporates principles of anti-discriminatory description practices.
This transition allows us to decouple the archival backend from the front-end presentation, ensuring long-term data accessibility, citability, and semantic interoperability. In our presentation, we will share the architectural overview, code-level considerations, and our reflections on working with DaSCH APIs in a real-world context, including:
Lessons learned in metadata crosswalks and transformation logic.
Technical caveats in version control, file transfers, and identifier management.
Challenges in aligning minimal computing approaches (CollectionBuilder) with robust backend infrastructures (DSP).
This case study illustrates how lightweight digital publishing environments can be effectively combined with national research infrastructures to deliver sustainable, standards-based access to historical research data. It also raises broader questions about infrastructural independence, scalability of humanities platforms, and the practical challenges of implementing FAIR principles in community-developed software ecosystems.

- Large-scale historical research project, initiated in 2011 by the Association for Basel History and carried out 2017–2026 at the University of Basel
- More than 70 researchers studying the history of Basel from the earliest settlements to the present day
- Funded with more than 9 million Swiss francs by the Canton of Basel-Stadt, the Lottery Fund, and private sponsors
. . .
- Specialized Team for Research Data Management and Public History
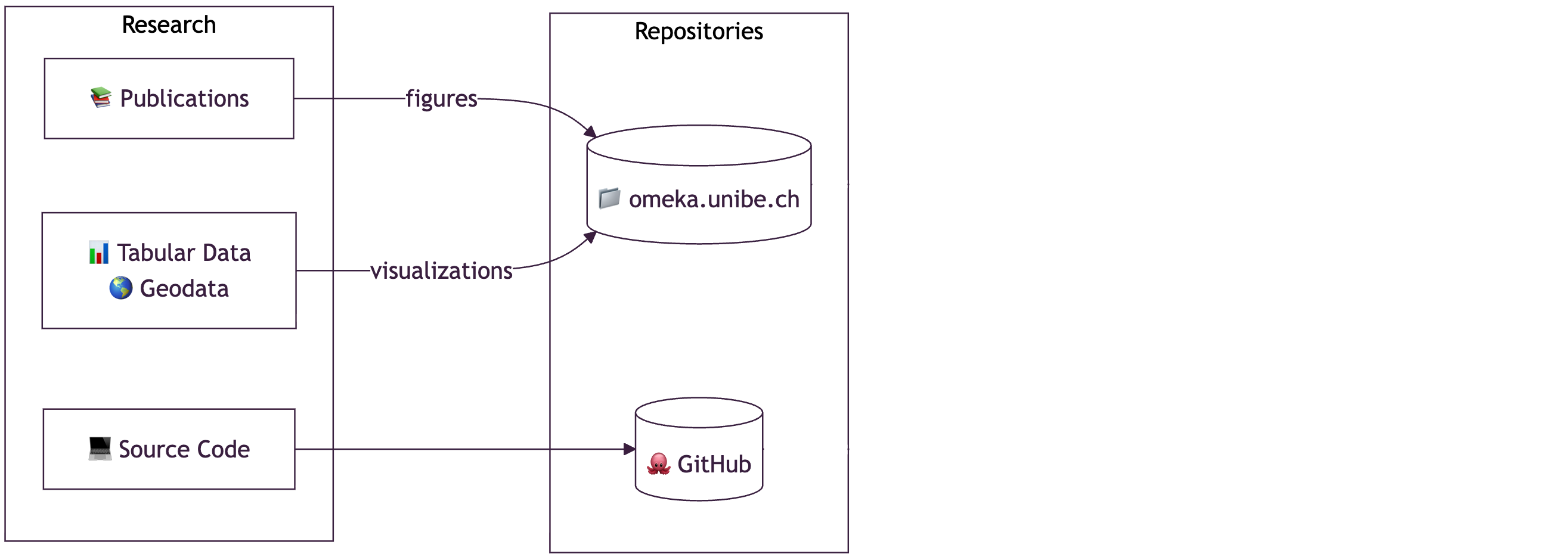
- Various research outputs (incl. books, papers, data stories, figures, and source code)
Research Data

Collecting and Managing Research Data
Public History with Research Data
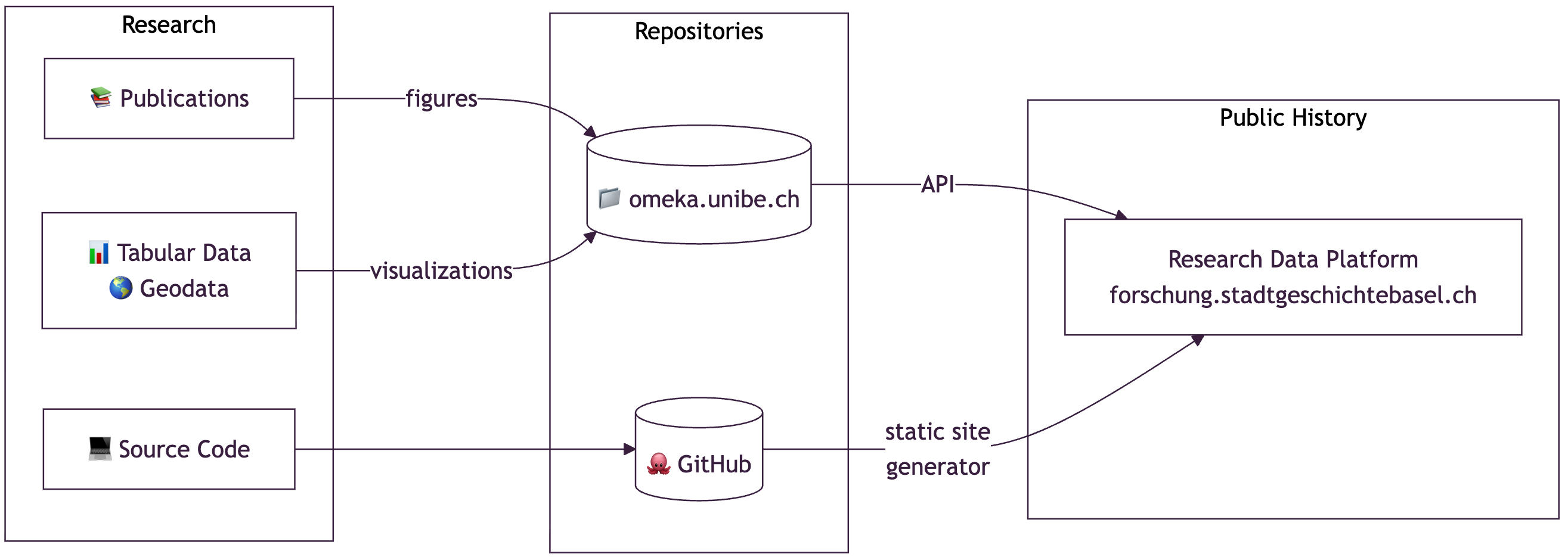
Archiving Research Data for the Long Run
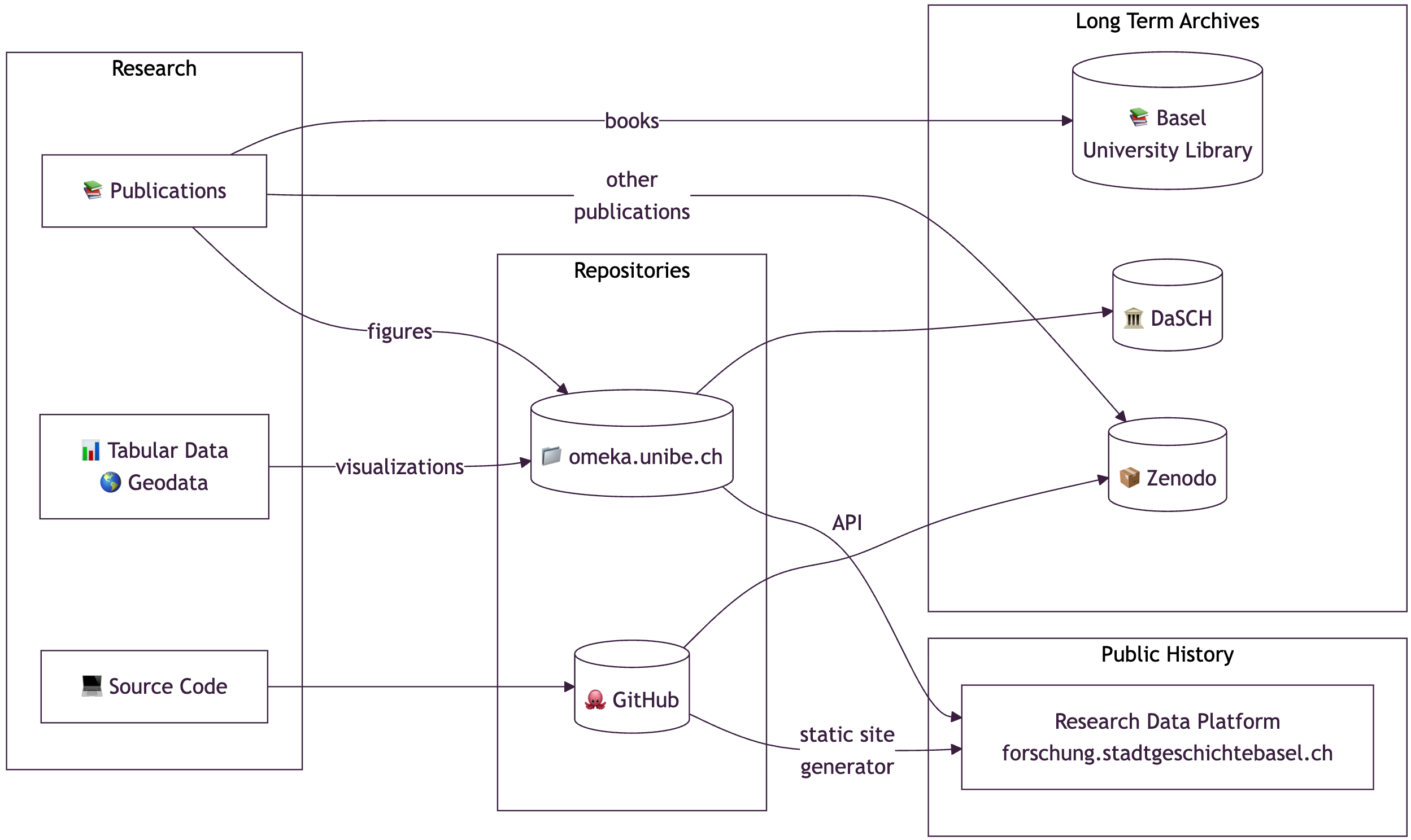
Long-Term Preservation
- Institutional sustainability: External dependencies (Omeka at UniBern) may not be permanently funded
- FAIR principles: Research data must be Findable, Accessible, Interoperable, and Reusable with proper metadata
- Citability: Researchers need persistent identifiers (PIDs) (stable URLs or DOIs) to reference historical materials
- Scalability: Current minimal computing approach (GitHub Pages) cannot handle large files
Where DaSCH Fits in: omeka2dsp
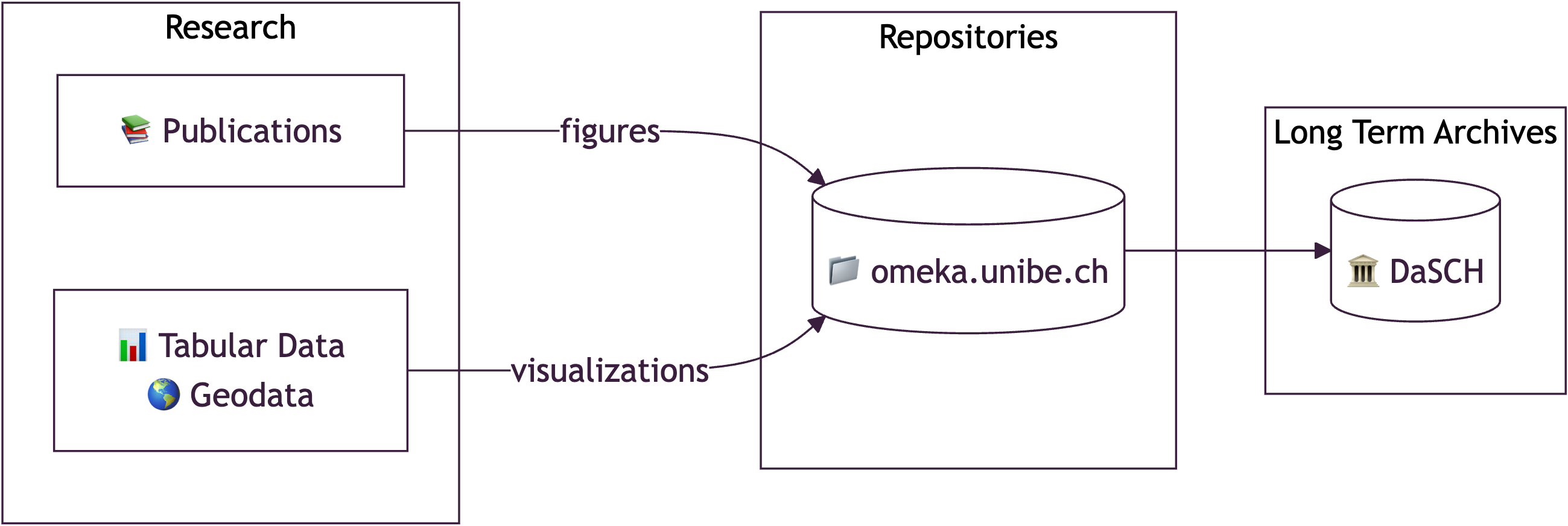
Challenges
- Data model differences (Omeka vs DaSCH)
- Metadata transformation and crosswalks
- Automation of deposit and version control
Data Model Differences
Omeka
Data Model Omeka (simplified 😇)
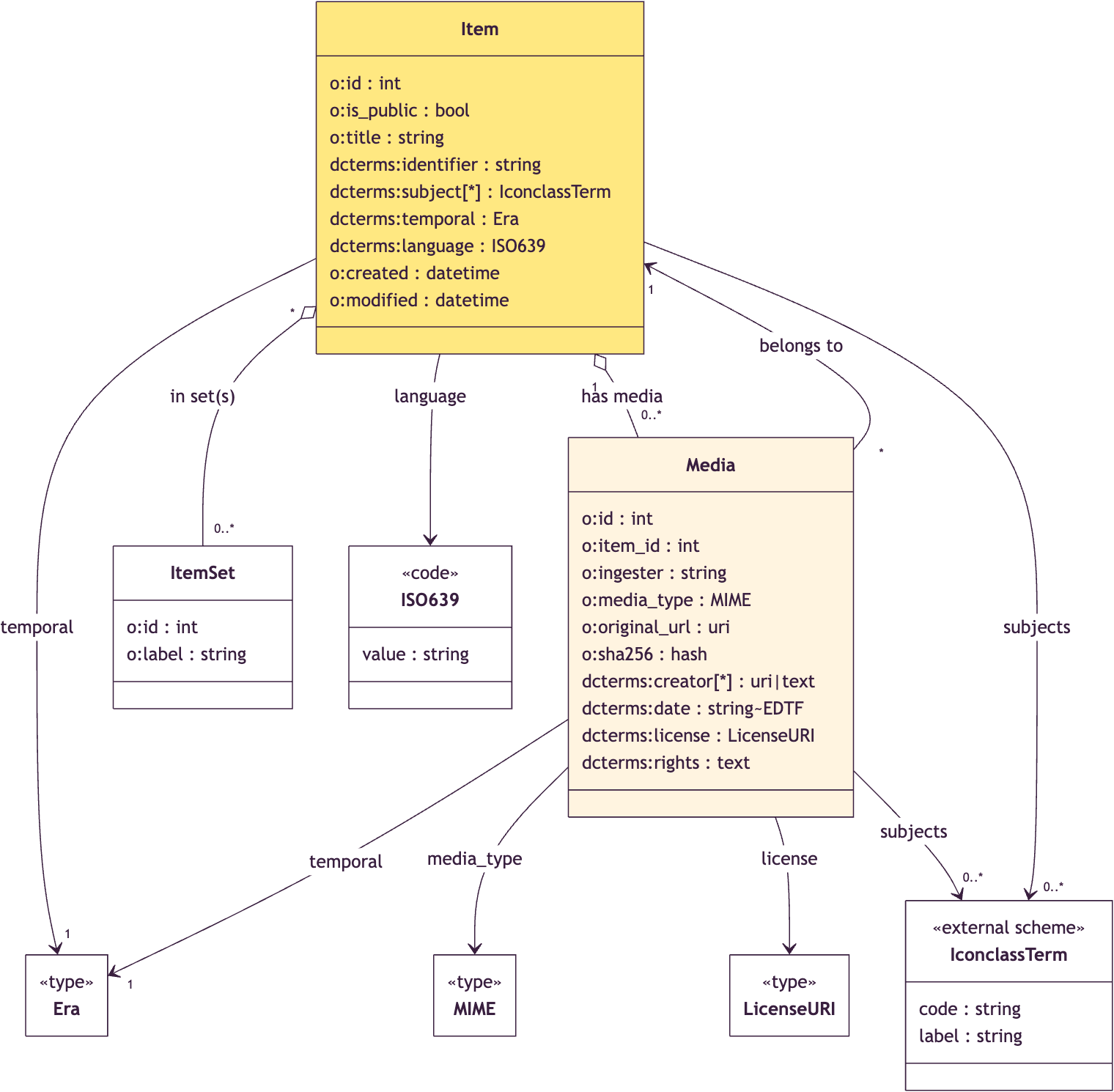
Data Model DaSCH (simplified 😅)

Key Differences
Modeling approach:
- DaSCH: Class hierarchy (
Resource→Document/Image…), explicit value classes (TextValue,ListValue). - Omeka S: Flat JSON-LD model (
Item,Media,ItemSet), Dublin Core–centric.
- DaSCH: Class hierarchy (
Normalization & constraints:
- DaSCH: Strict cardinalities and mandatory fields (
hasTitle [1]). - Omeka S: More flexible, “validation” through templates.
- DaSCH: Strict cardinalities and mandatory fields (
Hierarchy representation:
- DaSCH: Explicit
Parentclass andlinkToParentObject. - Omeka S: Uses field
ItemSetorMediato model relations.
- DaSCH: Explicit
Metadata Transformation
Data Validation
- Custom Python scripts using
pydanticfor schema validation as Omeka does not enforce strict validation - Validation also helps identify data quality issues
- Lots of manual cleaning required, all done in Omeka
Crosswalk Examples
| Omeka Property | DaSCH Property | Notes |
|---|---|---|
dcterms:title |
hasTitle |
Required in DaSCH (cardinality 1) |
dcterms:identifier |
hasIdentifier |
Not by DSP used for stable references |
dcterms:subject |
hasSubjectList |
Iconclass codes preserved |
dcterms:temporal |
hasTemporalList |
Era mapping required |
dcterms:creator |
hasCreatorList |
Multiple creators supported |
dcterms:license |
hasLicenseList |
License URIs validated |
| Media → Item | linkToParentObject |
Hierarchy explicitly modeled |
Version Control and Updates
- Challenge: DaSCH supports versioning, but requires careful planning
- Strategy:
- Initial deposit: Create new resources via REST API
- Updates: Use PUT requests with resource IDs to create new versions
- Identifier stability: ARK IDs remain constant across versions
API vs DSP-Tools
REST API Approach
- Direct HTTP requests
- Fine-grained control
- Supports versioning
- Complex error handling
- Used for updates
DSP-Tools Approach
- XML-based bulk import
- Good for initial deposits
- Less flexible for updates
- Comprehensive validation
- Used for large-scale ingestion
Our choice: Using dsp-tools for project setup and Rest API for ingestions/updates
omeka2dsp
Lessons Learned
- Metadata crosswalks and data quality: Mapping Dublin Core to the DaSCH ontology required custom logic and validation. Omeka’s flexible schema led to inconsistent metadata, demanding extensive cleaning.
- Identifiers and file handling: Synchronizing identifiers between Omeka and DaSCH proved complex. Large files (>100 MB) necessitated chunked uploads and tailored handling.
- Workflow timing and validation: Determining the right moment to shift from active curation to archival mode was key. Early validation with
pydanticschemas and subset testing prevented costly errors. - Documentation and reproducibility: Precise mapping documentation ensured consistency across transformations and supported reproducible workflows.
- Architecture and infrastructure: Decoupling archival (DaSCH) from presentation (CollectionBuilder) enhanced flexibility. Lightweight public interfaces can coexist with robust preservation systems when APIs enable automation.
Key Takeaways
For the Community
- Lightweight publishing can work with robust infrastructure
- FAIR principles are achievable in practice
- Decoupled architectures provide flexibility
- Open-source tools enable customization
For DaSCH Users
- Plan metadata transformation early
- Use validation extensively
- Consider hybrid API/DSP-Tools approach
- Document mapping decisions thoroughly